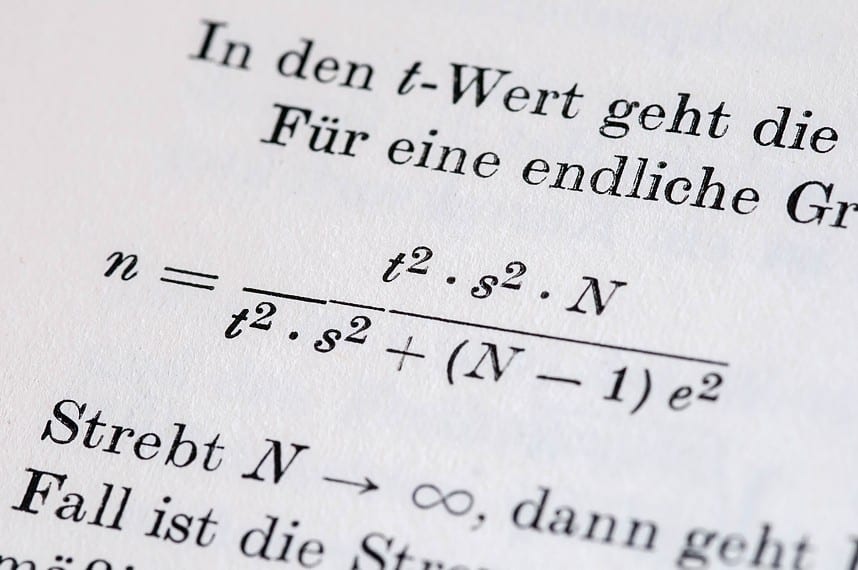

A/B tests are a popular approach for testing the success of changes made in the process of optimising websites. The version with changes is delivered to some of the users, while others see the unchanged original version. It is then measured which version generates more conversions and, after some time, it is established on a solid statistical basis which changes have been proven to increase conversions. This sounds as simple as it is desirable, but can lead to deception and disappointment if the methodological basis is disregarded.
The British data scientist Martin Goodson already explained in a lecture in 2014(1) why many positive A/B test results do not stand up to scientific scrutiny. The crux of A/B testing is the consideration of the test quality (statistical power). Goodson convincingly argues how, in still widespread practice, many A/B tests with insufficient discriminatory power lead to false positive results not being recognised and thus seemingly successful changes being implemented that at best have no effect, but at worst can even depress conversion figures.
How come?
Sample size
Goodson cites 6000 conversions (in words: six thousand conversions, not visits) as the minimum figure to be able to prove a performance improvement of 5% with sufficient statistical certainty. To prove an improvement of 10% - which is difficult to achieve in practice - 1600 conversions are still required. Not every online offer can come up with such conversion figures within a reasonable period of time.
Test runtime
Many A/B tests simply run for too short a time. The results of the ongoing test are usually subject to constant observation. If a variant proves successful, the test is quickly terminated - often after just a few weeks or even days. Such a procedure almost certainly leads to false positive results over several tests.
The minimum duration of an A/B test can and should, like all test power parameters, be statistically calculated in advance of the test. An exemplary calculation using the test duration calculator from converlytics (2) for a simple A/B test with 1000 visitors per day and variant, with a conversion rate of 3% and an expected improvement of a solid 5%, results in a minimum duration of 204 days to achieve a confidence level of 95%. With 100 visitors per day and variant, that's 2031 days (yes, that's actually a good five and a half years).
Too many tests
Test, test, test, then success will come quickly. This is a common maxim when using A/B tests and the appearance of success usually does indeed arise with this approach. In his presentation, Martin Goodson shows the statistical background to this typical and yet incorrect observation: as the number of tests increases, so does the number of false positives, and the lack of test power means that these are not recognised as such.
What to do?
The idea of A/B testing is by no means obsolete with Goodson's comments. It just goes without saying that you should know how to do it properly and whether it is a suitable tool for your own strategy. Careful preparation and attention to the statistical quality of the test are essential prerequisites for useful results.
If, in such a case, A/B tests are implemented at the cost of statistical power with samples that are too small and run for too short a time, and the successes that undoubtedly occur are only a sham, this is a waste of resources that would be better spent on other, non-test-driven areas of marketing optimisation.
To quote Martin Goodson himself:
"I don't think you can trust the data for everything. You should trust
your experience and your education, because people know how to sell
things to other people, they've been doing it for thousands of years."
Inspiring conclusion of a lecture that was as well-founded as it was sobering.
1: https://www.youtube.com/watch?v=MdkHLS0FPMk
2: https://converlytics.com/dauer-rechner-ab-test/
